Sosial Bookmarking Side med Høy Autoritet for Norsk SEO i 2026 - A2Bookmarks Norge
A2Bookmarks Norge er den ledende social bookmarking site i Norge, skreddersydd for norske brukeres behov. Denne sosiale bookmarking site for Norge lar deg enkelt lagre, organisere og dele dine favoritt-nettsteder og lenker med et brukervennlig grensesnitt. Enten du er en bedrift som ønsker å øke din online synlighet i det norske markedet, eller en privatperson som søker en bedre måte å administrere dine viktigste nettesider på, tilbyr A2Bookmarks de verktøyene du trenger. Øk autoriteten til din nettside og forbedre søkemotoroptimaliseringen din ved å bygge relevante tilbakekoblinger gjennom vårt norske bookmarking-nettverk. Som en av de beste norske social bookmarking sites for 2026, inviterer vi deg til å bli med i det voksende fellesskapet, oppdage nyttig innhold fra hele Norge, og forsterke din digitale tilstedeværelse med Norges fremste plattform for sosiale bokmerker. Utforsk de viktigste social bookmarking sites i det norske markedet for optimal SEO-ytelse.


Data Pipeline Architecture: Constructing AI-Ready, Scalable Systems anavcloudsanalytics.ai
One of an organization’s most important resources is data, but only if it can be put to use. Decisions are not made just based on raw data. It must be efficiently gathered, processed, and delivered. Data pipeline architecture can help with it. It specifies how data is sent from source systems to analytics platforms, how it is changed in route, and how consistently it gets to the systems and individuals that require it.
These days, having a well-designed data pipeline is essential as companies depend more on AI, automation, and real-time insights. Scalable growth, improved data quality, and quicker decision-making are all made possible by a robust architecture. A weak one results in mistakes, delays, and ongoing firefighting.
Data Pipeline Architecture: What Is It?
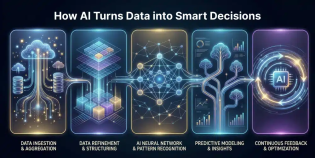
Fundamentally, data pipeline architecture is the structure that controls the movement of data throughout a company. The systems, procedures, and guidelines that control data from intake to delivery are included.
These essential layers are usually found in a contemporary pipeline:
Ingestion Layer: Gathers information from sources such as streaming platforms, databases, APIs, and SaaS solutions. Both batch and real-time data are supported.
Storage Layer: Data lakes, warehouses, or lakehouse systems are used to store raw or processed data.
Transformation Layer: Prepare data for analytics or AI use by cleaning, organizing, and enhancing it.
Orchestration Layer: Oversees dependencies, scheduling, and processes throughout the pipeline.
Serving Layer: Provides information to dashboards, machine learning systems, and BI tools.
Observability Layer: Tracks performance, data quality, and pipeline health.
Every layer is essential to guaranteeing fast, accurate, and accessible data.
Common Data Pipeline Patterns
There’s no one-size-fits-all pipeline. The right design depends on your business needs, data volume, and latency requirements. Some widely used patterns include:
ETL (Extract, Transform, Load): Data is transformed before loading into storage. Ideal for structured and regulated environments.
ELT (Extract, Load, Transform): Data is loaded first and transformed within the warehouse. Common in cloud-native systems.
Streaming Pipelines: Process data in real time for use cases like fraud detection or live analytics.
Batch + Streaming Hybrid: Combines real-time ingestion with batch processing for efficiency.
Lambda and Kappa Architectures: Advanced models for handling large-scale data processing.
Reverse ETL: Sends processed data back into operational tools like CRMs and marketing platforms.
Choosing the right pattern depends on how fast you need insights and how complex your data workflows are.
Why Cloud-Native Architecture Matters
Modern pipelines are increasingly built on cloud platforms. Cloud-native data pipeline architecture offers several advantages:
Scalability: Automatically adjusts resources based on demand
Flexibility: Separates storage and compute for cost efficiency
Integration: Easily connects with modern tools and services
Observability: Built-in monitoring and alerting features
This flexibility is especially important for organizations managing large, diverse datasets across multiple systems or cloud environments.
Designing for AI and Analytics
AI has changed the requirements for data pipelines. It’s no longer just about reporting—it’s about powering intelligent systems. AI-ready pipelines must support:
Consistent data for training and inference
Data versioning for model tracking
Low-latency delivery for real-time decisions
Support for unstructured data like text and images
Pipelines now also play a role in feeding AI agents and enabling automation across the data lifecycle.
Common Pitfalls to Avoid
Many pipeline failures aren’t obvious—they happen quietly over time. Some common mistakes include:
Ignoring observability and monitoring
Treating transformation as an afterthought
Failing to handle schema changes
Over-engineering complex architectures too early
Lacking governance and data quality controls
Avoiding these issues requires thoughtful planning and a focus on long-term scalability.
Concluding Remarks
Data pipeline architecture is now a strategic business skill rather than just a backend issue. It has a direct effect on how fast and efficiently a company can use its data.
Businesses can transform their data into insights, automation, and competitive advantage by investing in pipelines that are scalable, visible, and AI-ready.
Source: https://www.anavcloudsanalytics.ai/blog/data-pipeline-architecture-build-scalable-ai-ready-systems/
voters
Report Story Related Stories





Recent Stories